Product
24 April 2024
Introducing VESSL Serve — Deploy custom models & generative AI applications and scale inference with ease
Deploy any models to any clouds at any scale in minutes without wasting hours on API servers, load balancing, automatic scaling, and more
Companies are actively seeking ways to deploy their own purpose-built Llamas, Mistrals, and Stable Diffusions, fine-tuned with proprietary datasets, and better-streamline this process↗. With VESSL Run, we’ve been helping teams like Scatter Lab↗ and Yanolja NEXT↗ customize open-source frontier models to build Asia’s most advanced LLMs like Pingpong↗ and EEVE↗. However, fine-tuning and customizing AI & LLMs is only half the battle. Deploying these models and scaling inference to multiple models and millions of requests is an entirely different challenge — from running a compute instance to performance & cost optimization.
Today, with VESSL Serve, we are excited to extend our AI infrastructure to the deployment stage of the model lifecycle and help teams easily put their custom models into use at scale, reliably. By providing an easy-to-use, common workflow across the team, VESSL Serve eliminates the (1) inefficiencies of setting up repetitive infrastructures for each model service, and the (2) poor experiences of managing fragmented codebase, models, and services.
Deploy vLLM-accelerated Llama 3
Follow along with our quickstart guide to deploy vLLM-accelerated Llama 3 on the cloud
The easiest way to deploy custom models
When designing VESSL Serve, we wanted to provide the best developer experience as teams go through the three common logics of model deployment — (1) making models readily available, (2) functioning efficiently under different load conditions, and (3) maintaining performant latency and throughput levels — while ensuring availability, scalability, and reliability.
Making models readily available
We abstracted the complex process of creating model API servers into a single command. Upon registering a fine-tuned model on our model registry and defining a set of model APIs, developers can make their models readily available on the cloud with the vessl serve command. Take a look at the service spec for our vLLM-accelerated Llama 3 defined in quickstart.yml↗ which
- Launches an L4-accelerated instance on our managed cloud.
- Defines the service environment using a Docker image.
- Creates a vLLM-enabled text generation endpoint as defined in
api-test.py↗. - Uses Llama 3 hosted on Hugging Face as the model.
name: vllm-llama-3-server
message: Quickstart to serve Llama3 model with vllm.
image: quay.io/vessl-ai/torch:2.1.0-cuda12.2-r3
resources:
cluster: vessl-gcp-oregon
preset: gpu-l4-small-spot
run:
- command: |
pip install vllm
python -m vllm.entrypoints.openai.api_server --model $MODEL_NAME
env:
MODEL_NAME: casperhansen/llama-3-8b-instruct-awq
ports:
- port: 8000
service:
autoscaling:
max: 2
metric: cpu
min: 1
target: 50
monitoring:
- port: 8000
path: /metrics
expose: 8000vessl serve revision create -f quickstart.yaml
This service spec, along with the vessl serve command abstracts the complex backends required for everything from acquiring compute to creating an API endpoint, and provides a common template that developers can quickly tweak to scaffold out production services — using their own on-prem machines or LLMs hosted on our model registry, for example.
Once the API server gets up and running, you can start using the endpoints to use the model in production.
python api-test.py \
--base-url "https://{YOUR-SERVICE-ENDPOINT}" \
--prompt "Can you explain the background concept of LLM?"Functioning efficiently under different load conditions
We built VESSL Serve with large-scale production in mind — helping teams scale from a single model to tens or even hundreds, and future-proofing services to handle billions of requests. With support for autoscaling, traffic routing, and more, VESSL Serve ensures that your AI services maintain top performance under various load conditions while improving responsiveness, availability, and resource utilization.
ports:
- name: service-1
type: http
port: 8000
- name: service-2
type: http
port: 8001
service:
autoscaling:
max: 2
metric: cpu
min: 1
target: 50
expose: 8000Autoscale & instant cold start — Our autoscale automatically scales up compute during peak usage. When traffic is low, these instances are spun down to save resources, but when a request comes in, our cold start ensures that the model gets up and going again in a few seconds.

Model routing & revisions — By deploying multiple versions of models and setting different traffic weights, teams can not only A/B test your versioned models, but also keep their AI services up and running through fallbacks in case of a model failure.

Maintaining performant latency and throughput levels
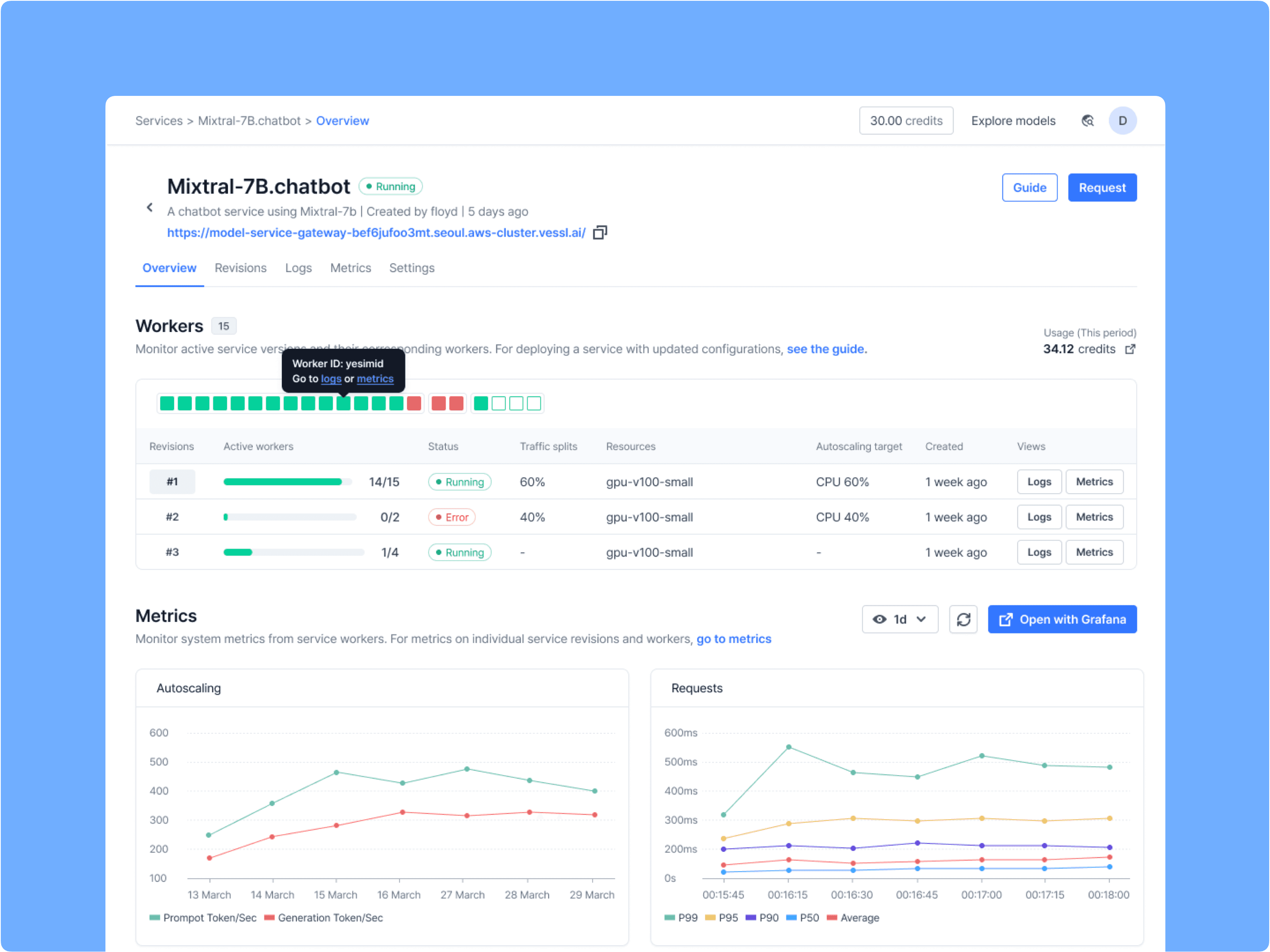
For fast and scalable inference, we made sure VESSL Serve works seamlessly with inference optimization tools, from FastAPI to LLM-specific engines like vLLM↗, NVIDIA TensorRT↗, and Hugging Face Text Generation Inference↗ (TGI). Once integrated, VESSL Serve brings up a monitoring dashboard using the real-time key system and performance metrics from these inference engines so you don’t have to deal with observability tools like Prometheus and Grafana.

What’s next — Streamlining fine-tuning to deployment
Since releasing our first product in 2020, we released several milestone products like VESSL Serve built on the foundation of our core product VESSL Run. In the next few months, we will be bringing a full redesign to our platform — fixing unbalances in the overall design and removing overheads in between our products — to bring coherency in the model lifecycle on VESSL AI, and thereby further reduce the time to launch a model. Here’s a sneak peek.

Meanwhile, try out VESSL Serve by following along with our quickstart guide to deploy vLLM-accelerated Llama 3 on the cloud. To help you get started, we are giving out $30 in GPU credits. For a more in-depth guide and our full compute options & prices, please refer to our docs↗.
https://github.com/vessl-ai/examples/tree/main/services/service-quickstart

Yong Hee
Growth Manager

Intae Ryoo
Product Manager
Try VESSL today
Build, train, and deploy models faster at scale with fully managed infrastructure, tools, and workflows.