인사이트
15 July 2025
MLOps란? AI 프로젝트에 필요한 이유와 구축 방법
MLOps 뜻, 필요성, DevOps와 LLMOps와의 비교까지 알아보세요.
최근 AI 기술이 발달하면서 데이터 수집과 관리, 그리고 머신러닝 프로젝트가 많아지면서 MLOps가 주목받고 있습니다. AI를 더 쉽고 안정적으로 운영하고 싶다면 MLOps부터 이해해야 합니다. MLOps란 무엇이고, 어떻게 활용할 수 있는지 알려드립니다.
MLOps란?
MLOps란 Machine Learning Operations (머신러닝 운영)의 약자로, 머신러닝 모델의 안정적인 개발과 운영을 유지, 관리, 배포, 모니터링 등의 서비스를 효율적으로 제공하기 위해 생겨난 프레임워크 입니다.
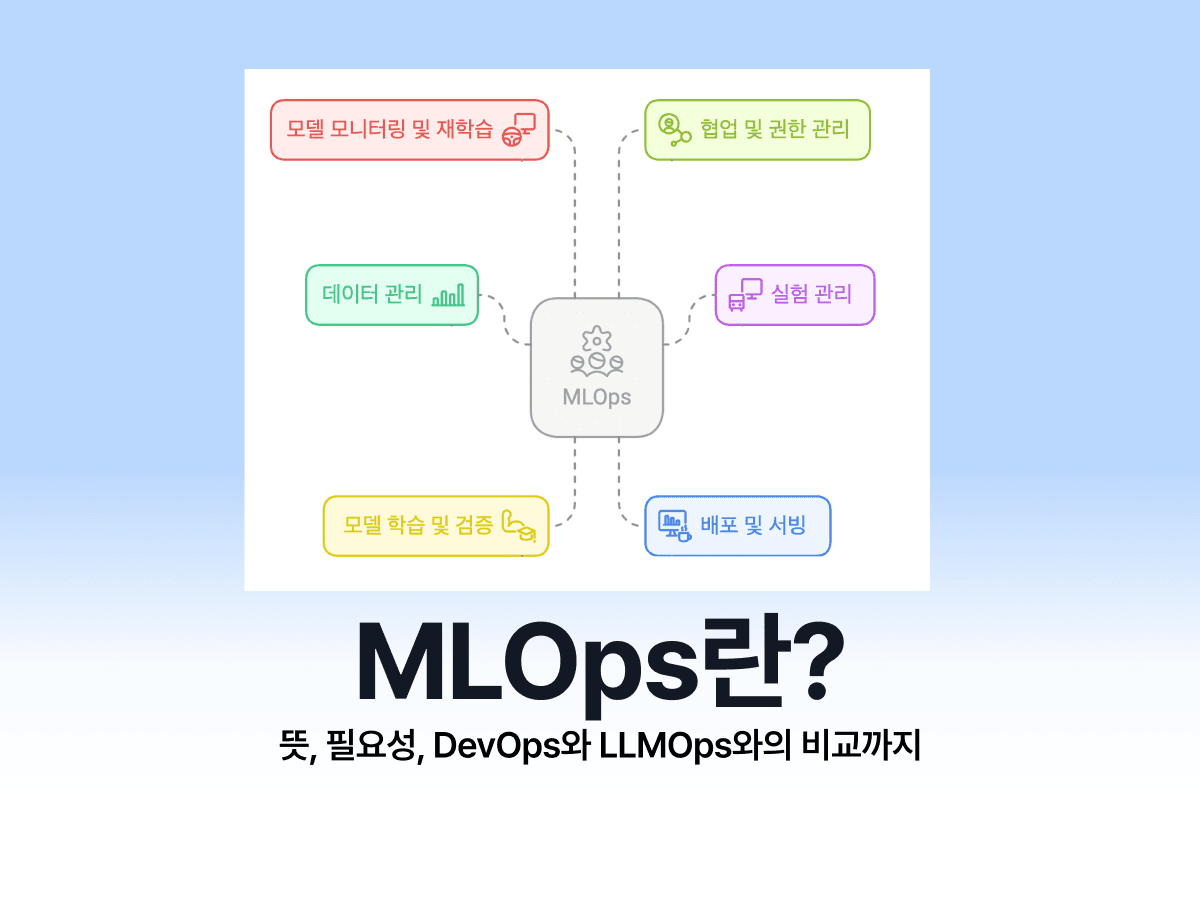
MLOps의 주요 구성 요소
MLOps는 크게 데이터 관리, 모델 개발, 배포 및 서빙, 그리고 모델 모니터링과 재학습을 통해 머신러닝 수명 주기를 관리합니다.

데이터 관리 (Data Management)
MLOps에서는 데이터를 수집하고 버전 관리하며 품질을 검증합니다. 데이터가 바뀌면 모델 성능도 변하기 때문에 같은 데이터셋으로 실험을 재현할 수 있어야 하기 때문입니다.
실험 관리 (Experiment Tracking)
MLOps는 모델 학습 과정(하이퍼파라미터, 코드, 결과)을 체계적으로 기록하고 비교하기도 합니다. 이 과정을 통해 모델 성능이 가장 좋은 설정을 추적 가능하게 만들어 운영 안정성을 높일 수 있습니다.
여기서 주의할 사항은:
- 하이퍼파라미터뿐만 아니라 개발환경, 커맨드, 로그, 메트릭 등 실험과 관련된 모든 정보를 기록합니다.
- 기록된 정보로 모델을 정확히 재현할 수 있는지 확인합니다. 특히, 데이터셋이 수시로 바뀌는 경우, 실험을 실행할 때마다 데이터셋의 버전을 기록하지 않으면 모델이 재현되지 않을 수 있습니다.
- 기록된 정보를 쉽게 찾아볼 수 있도록 중앙화된 저장소에 구조화하여 저장합니다. 시간이 지나도 해당 정보를 쉽게 찾아볼 수 있도록 엑셀이나 로컬환경에 저장하지 않고, 팀원과 상시 공유되는 중앙화된 저장소에 저장하는 것이 좋습니다.
모델 학습 및 검증 (Model Training & Validation)
MLOps의 이 과정에서는 데이터셋으로 모델을 학습시키고 다양한 평가 지표로 성능을 검증합니다. 이를 통해 오버피팅과 언더피팅을 방지하고 실제 환경에서 동작할 수 있는 신뢰성 높은 모델을 확보할 수 있습니다.
배포 및 서빙 (Deployment & Serving)
학습된 모델을 API나 애플리케이션으로 배포하여 실시간으로, 또 새로운 데이터로 예측 서비스를 제공합니다. 이 과정은 개발 환경과 배포 환경 간 차이를 줄여서 예상치 못한 오류를 방지할 수 있습니다.
모델 모니터링 및 재학습 (Monitoring & Retraining)
배포된 모델의 예측 성능을 실시간으로 검사하고 데이터 드리프트나 성능 저하의 경우 재학습 파이프라인을 작동시킵니다. 모델 성능은 시간이 지나면서 떨어질 수 있어 이를 자동으로 감지하고 해결하는 것이 중요합니다.
협업 및 권한 관리 (Collaboration & Governance)
이때 데이터 사이언티스트, ML 엔지니어, 운영팀 간 협업 환경을 표준화하고 접근 권한을 체계적으로 관리하여 보안성과 생산성을 유지합니다.
이처럼 MLOps는 단일 툴로 모든 요소를 처리하기 어렵기 때문에, 베슬에이아이의 VESSL과 같은 통합 플랫폼을 통해 각 구성 요소를 한 번에 관리하는 것이 점점 표준이 되고 있습니다.
MLOps의 필요성
MLOps는 앞서 설명한 것처럼 데이터 준비, 모델 훈련, 모델 배포와 같이 복잡한 구성 요소가 많이 모여있어 대량으로 생산하기 쉽지 않습니다. 또한 데이터 사이언스, ML 엔지니어링, 그리고 운영팀에 이르기까지 여러 그룹의 협업도 필요합니다.
이때 MLOps를 통해 AI 솔루션 제작, 데이터 관리, 그리고 협업의 어려움과 같은 문제점들을 극복할 수 있습니다.
효율성
MLOps는 머신러닝 수명 주기 전반을 자동화해, 모델의 개발부터 배포, 유지보수까지 더 쉽고 빠르게 처리할 수 있습니다.
확장성
대용량 데이터나 복잡한 워크플로우도 유연하게 확장할 수 있어, 기업의 AI 운영 규모를 자유롭게 키울 수 있습니다.
안정성
모델의 정확성과 일관성을 유지해 오류나 예기치 않은 결과를 최소화하고, 신뢰성 높은 서비스를 제공합니다.
협업 강화
데이터 사이언티스트, ML 엔지니어, 운영팀이 동일한 프레임워크와 도구를 사용해 원활하게 협업할 수 있습니다.
비용 절감
반복적이고 수동적인 작업을 자동화하여 인적 리소스를 효율적으로 활용하고, 불필요한 비용을 줄일 수 있습니다.
MLOps 플랫폼이란?
MLOps 플랫폼은 데이터 사이언티스트와 머신러닝 엔지니어에게 일관된 협업 환경을 제공해, 반복적인 데이터 처리부터 실험 추적, 모델 관리, 배포, 모니터링까지 전 과정을 자동화하고 간편하게 관리할 수 있도록 돕는 통합 솔루션입니다.
일반적으로 MLOps 플랫폼은 다음을 지원합니다:
- 반복 데이터 탐색과 피처 엔지니어링(Feature engineering)
- 실시간 공동 작업 및 실험 관리
- 모델 배포(Deployment)와 서비스 운영 자동화
- 배포 후 실시간 모니터링과 성능 추적
이러한 기능 덕분에 MLOps 플랫폼은 머신러닝 수명 주기 전체의 운영과 동기화를 효율적으로 자동화하여 생산성을 극대화하고 오류를 줄여줍니다.
대표적인 MLOps 플랫폼 중 하나인 베슬에이아이의 VESSL 플랫폼은 복잡한 설정 없이도 머신러닝 파이프라인을 빠르게 구축하고 운영할 수 있도록 지원합니다.
데이터 탐색, 실험 추적, 학습, 배포, 모니터링까지 전 과정을 하나의 플랫폼에서 처리할 수 있어 효율적인 AI 워크플로우를 구현할 수 있습니다.
특히 VESSL 플랫폼은 다음과 같은 장점을 제공합니다:
- GPU 인프라 구성과 MLOps 환경을 동시에 제공
- 온프레미스, 클라우드, 퍼블릭 클라우드 연동 모두 지원
- 학습/추론/배포 자동화 및 실험 관리 기능 내장
- 시간당 $1.80부터 시작하는 A100과 같은 고성능 GPU 자원으로 비용 효율 극대화(GPUaaS)
- 연구자와 관리자 모두를 위한 UI/UX와 RBAC 기반 자원 관리
VESSL의 실제 사용 사례와 도입 효과를 더 알아보시려면 아래 글을 참고해 주세요.머신러닝 운영(MLOps) 플랫폼 VESSL 소개 — GPU 도입부터 학습/개발/배포까지 한 번에!
MLOps 플랫폼 도입 시 고려 사항
조직 내 머신러닝 성숙도 평가
MLOps 플랫폼을 도입하기 전에 조직의 데이터 활용 능력과 머신러닝 성숙도를 파악해야 합니다.
기술 스택과 팀 구성
데이터 과학자, 엔지니어, 운영 전문가 간의 협업이 가능한 환경을 조성해야 합니다.
비용과 ROI 분석
초기 투자 비용과 예상되는 ROI를 명확히 평가하여 적절한 도구와 인프라를 선택하는 것이 중요합니다.
MLOps의 주요 도구
데이터 엔지니어링 도구
Apache Spark, Apache Airflow 등은 데이터 파이프라인 자동화와 병렬 처리를 지원해 대용량 데이터를 효율적으로 처리합니다.
모델 학습 도구
TensorFlow, PyTorch, VESSL Run은 모델 개발과 실험 관리에 널리 쓰이는 프레임워크입니다. 특히 VESSL Run은 클라우드 기반 실험 관리와 자동화된 학습 환경을 제공해 빠른 실험 반복을 가능하게 합니다.
배포 및 서빙 도구
Docker, Kubernetes, MLflow, VESSL Serve는 모델 컨테이너화 및 안정적인 배포를 돕습니다. VESSL Serve는 직관적인 UI와 자동화 기능으로 빠른 배포와 확장, 실시간 모니터링까지 지원합니다.
MLOps 파이프라인 구축 방법
MLOps 파이프라인은 주로 아래 단계로 구성됩니다. 각 단계는 선택한 도구와 인프라에 따라 구현 방식이 달라질 수 있습니다.

1) 데이터 수집 및 전처리 (Data Collection and Preparation)
머신러닝 모델 학습에 필요한 데이터를 수집하고 결측치, 이상치 등을 처리하여 모델 학습에 적합한 형식으로 정제합니다.
데이터 품질은 전체 모델 성능에 직접적인 영향을 미치므로 스키마 검증이나 이상치 탐지 같은 데이터 검증(Data Validation) 작업도 합니다.
2) 모델 학습 및 튜닝 (Model Training and Tuning)
정제된 데이터로 모델을 학습 시킨 후 하이퍼파라미터를 조정하여 성능을 최적화 합니다. 이때 실험 설정, 코드, 로그, 메트릭 등을 체계적으로 기록하여 실험 환경을 재현 가능하게 만드는 것이 중요합니다. 또한 Git, DVC 등의 도구를 활용하면 코드와 데이터 버전을 더 쉽고 효율적이게 통합 관리할 수 있습니다.
3) 모델 테스트 및 검증 (Model Testing and Validation)
학습된 모델을 다양한 테스트용 데이터셋으로 정확도, 정밀도, 재현율 등 성능 지표를 검증합니다. 기존 모델과 비교하거나 다양한 세그먼트에서의 성능을 평가해 일관성이나 향상 여부를 확인하기도 합니다.
4) 모델 배포 (Model Deployment)
품질 기준을 충족한 모델은 API 또는 서비스 형태로 운영 환경에 배포됩니다. Docker, Kubernetes, VESSL Serve 등을 사용하면 배포를 쉽게 자동화하고 환경 간 차이를 줄여 예측 오류를 방지할 수 있습니다.
5) 모델 배포 및 모니터링 (Model Monitoring and Maintenance)
배포된 모델의 성능을 실시간으로 모니터링하고 데이터 드리프트나 성능 저하가 감지되면 자동으로 재학습 워크플로우가 작동하도록 합니다. 이는 모델이 계속해서 최신 데이터를 반영하고 일관된 품질을 유지할 수 있게 해줍니다.
파이프라인 구성 시 핵심 요소
프레임워크 및 도구 선택
Kubeflow, MLflow, VESSL과 같은 MLOps 플랫폼을 활용하면 각 단계의 자동화 및 통합이 쉬워집니다.
특히 VESSL은 온프레미스 또는 클라우드 환경을 유연하게 선택할 수 있는 구조로, 인프라 선택의 폭이 넓습니다.
워크플로우 자동화
데이터 처리, 학습, 배포 등 각 작업은 스케줄링되어 자동 실행되며, 단계별 로그를 통해 실행 상태를 실시간으로 모니터링할 수 있습니다.
모델 레지스트리 및 Feature Store
모델 버전, 하이퍼파라미터, 성능 평가 결과 등을 기록하는 모델 레지스트리(Model Registry)와 반복 실험 시 일관된 입력을 주는 Feature Store는 대규모 실험 환경에서 재현성과 안정성을 높이는 데 중요한 역할을 합니다.
협업과 권한 관리
역할 기반 접근 제어(RBAC)를 통해 팀별 권한을 나누고 실험 기록과 변경 이력을 중앙화해 협업 효율과 보안성을 동시에 확보할 수 있습니다.
MLOps와 LLMOps, DevOps, DataOps, AIOps와의 차이점
MLOps에 사용되는 Ops는 ‘Operations’의 줄임말로, 특정 기술 영역의 개발과 운영을 효율적이고 안정적으로 관리하기 위한 방법론과 도구 체계를 의미합니다. MLOps를 중심으로 다양한 Ops 개념들과의 차이를 비교해보면 다음과 같습니다.
MLOps vs. LLMOps 차이
MLOps와 LLMOps는 둘 다 머신러닝 모델을 실제 서비스에 적용하고 운영하기 위한 방법론이지만, LLMOps는 대규모 언어 모델(LLM)에 특화된 운영 방식입니다. 따라서 데이터 관리, 모델 운영 방식, 그리고 성능 개선 방법에 차이가 있습니다.
데이터 관리
MLOps는 구조화된 데이터셋 준비와 관리가 중요한 방면, LLMOps는 프롬프트, 임베딩, 벡터DB 관리가 중요합니다.
모델 운영
MLOps는 다양한 크기의 모델을 반복 학습하고 주기적으로 배포하는 데 초점을 맞추며, 모델 학습 파이프라인 자동화가 중요합니다. 반면, LLMOps는 거대한 언어 모델을 API 기반으로 서빙하고, 이 과정에서 GPU 사용 최적화, 추론 속도(레이턴시) 관리, 모델 캐싱 등 운영 효율성이 중요합니다.
성능 개선 방법
MLOps는 새로운 데이터 수집 후 재학습 주기가 짧은 편이지만, LLMOps는 완전 재학습보다는 프롬프트 엔지니어링, 파인튜닝, RAG로 성능을 개선합니다.
정리하면, MLOps는 모델 중심 운영, LLMOps는 LLM 중심 운영(프롬프트+추론+RAG 중심)으로 특화되어 생성형 AI 및 대규모 언어 모델의 실시간 서비스 운영에 최적화된 것이 가장 큰 차이입니다. 단, 실제 현장에서는 MLOps와 LLMOps의 경계가 완전히 분리되기보다는, LLMOps가 MLOps의 원칙을 확장·보완하는 형태로 적용되는 경우도 많습니다.
MLOps vs. DevOps 차이
MLOps는 ML(머신러닝)과 DevOps(데브옵스)를 결합한 개념으로 정의되기도 합니다. MLOps는 지속적인 데이터 수집과 모델 재훈련이 필요하다는 점에서 DevOps와 차별화됩니다. 이는 데이터 중심의 문제를 해결할 수 있는 맞춤형 프로세스가 필요함을 의미합니다. 구체적인 차이점은 아래와 같습니다:
운영 대상
MLOps는 머신러닝 모델의 수명 주기 전반을 관리하는데, DevOps는 애플리케이션 및 소프트웨어의 빌드, 테스트, 배포, 운영을 관리합니다.
데이터 관리
MLOps는 학습 데이터셋 준비 및 데이터 버전 관리와 Feature Store 관리가 중요하며, DevOps는 주로 애플리케이션 코드, 테스트 케이스, 배포 스크립트 등을 관리합니다.
운영 주기
MLOps는 데이터 수집 → 모델 학습 → 검증 → 배포 → 모니터링 및 재학습 주기가 반복되며, DevOps는 코드 작성 → 빌드 → 테스트 → 배포 → 모니터링 주기가 반복됩니다.
핵심 기술
MLOps는 모델 학습 파이프라인 자동화, 실험 관리, Model Registry, Feature Store, CI/CD for ML을 사용하고 DevOps는 CI/CD, IaC(Infrastructure as Code), 모니터링, 자동 배포, 롤백 등을 사용합니다.
따라서 MLOps는 데이터와 모델의 변화에 따른 지속적 학습과 추론 성능 유지에 초점을 두고, DevOps는 소프트웨어 기능의 지속적 통합 및 배포 자동화에 초점을 둡니다. DevOps의 원칙이 ML 특유의 데이터·모델 중심 운영 요구에 맞춰 확장된 것이 MLOps라고 할 수 있습니다.
MLOps vs. DataOps 차이
DataOps는 데이터 파이프라인의 데이터 수집, 정제, 분석, 배포 과정의 품질과 속도를 향상시키려고 합니다. 이는 MLOps의 전 단계로, 모델 학습 전에 필요하는 데이터 준비를 합니다. 구체적인 차이는 다음과 같습니다:
운영 대상
MLOps는 머신러닝 모델의 학습 및 운영이 대상인데, DataOps는 데이터 파이프라인과 데이터 품질 관리가 대상입니다.
데이터 관리
MLOps는 실험 재현성이 중요한데, DataOps는 ETL, 데이터 카탈로그, 테스트 자동화를 통한 데이터 신뢰성 확보가 핵심입니다.
운영 주기
MLOps는 모델의 주기적 재학습 및 성능 검증 중심이며,
DataOps는 데이터 수집부터 분석까지의 파이프라인 최적화와 지속적 데이터 품질 유지가 중심입니다.
핵심 기술
MLOps는 ML pipeline 도구(Kubeflow, VESSL), 실험 관리(MLflow), CI/CD, Model Registry 등이 포함되고 DataOps는 Airflow, dbt, Great Expectations, Kafka, Data Catalog, Data Quality platform 등이 포함됩니다.
정리하면, MLOps는 ‘모델 중심의 운영 자동화’지만 DataOps는 ‘데이터 중심의 운영 자동화’ 라는 점이 큰 차이입니다.
MLOps vs. AIOps 차이
AIOps는 AI 기술을 활용해 IT 인프라(서버, 네트워크, 클라우드)의 로그, 메트릭 데이터를 분석하여 이상 탐지 및 자동 대응을 자동화합니다. MLOps와는 적용 분야가 달라서 MLOps는 AI 개발자 입장으로 AI 모델을 개발하고 제품화하는데 집중하고, AIOps는 IT 운영자 입장을 가져 AI를 운영 현장의 효율화 도구로 활용합니다.
운영 대상
MLOps는 ML 모델, AIOps는 IT 시스템/인프라를 관리합니다.
데이터 관리
MLOps는 모델 학습용 데이터셋 준비와 관리가 핵심이며, AIOps는 실시간 로그, 메트릭, 이벤트 데이터를 수집하고 분석합니다.
운영 주기
MLOps는 모델 성능 유지·개선을 위해 주기적 재학습이 포함되며, AIOps는 지속적인 모니터링과 실시간 이상 탐지가 됩니다.
핵심 기술
MLOps는 ML pipeline, CI/CD for ML, Feature Store, Model Registry, 실험 관리 도구(예: MLflow, VESSL 등)를 사용합니다. AIOps는 로그/메트릭 수집 도구(예: Prometheus, ELK), 실시간 이상 탐지(Anomaly Detection), 경보 자동화 시스템 등을 사용합니다.
요약하면, MLOps는 ‘AI 서비스를 만드는 것’인 반면, AIOps는 ‘AI로 IT 운영을 최적화하는 것’입니다.

MLOps의 전망
MLOps는 앞으로도 AI와 머신러닝 활용이 일상화되면서 더욱 필수적인 기술로 자리 잡을 전망입니다.
Fortune Business Insights에 따르면 글로벌 MLOps 시장 규모는 2022년 약 7억 3,630만 달러에서 2029년까지 연평균 39.3%의 높은 성장률을 기록하며 60억 달러 이상으로 성장할 것으로 예측됩니다.
기업들은 점점 더 복잡해지는 머신러닝 모델과 대규모 데이터셋을 효과적으로 관리하고 운영하기 위해 안정적이고 자동화된 파이프라인에 대한 수요를 계속 확대하고 있습니다.
결국 MLOps는 단순한 툴 모음을 넘어 AI를 책임감 있고 투명하게 운영하기 위한 핵심 전략이자 기업 경쟁력을 높이는 필수 요소로 자리매김할 것입니다.
복잡한 인프라 설정 없이 GPU 인프라부터 파이프라인 자동화, 실험 관리, 배포까지 한 번에 연결할 수 있는 베슬에이아이의 플랫폼에 관심이 있으면 아래 버튼을 통해 문의주세요!
참고 자료:
https://www.databricks.com/kr/glossary/mlops
https://elice.io/ko/newsroom/whats_mlops
https://cloud.google.com/discover/what-is-mlops?hl=ko
https://blog.naver.com/suresofttech/223538409824
https://julie-tech.tistory.com/2
https://blog.naver.com/watch_all/222720454115
https://csshark.tistory.com/78
https://www.tpcg.co.kr/post/llmops-vs-mlops-vs-aiops-vs-devops의-차이점-이해하기
https://www.fortunebusinessinsights.com/ko/mlops-market-108986

Alice Lee
Growth Manager
Try VESSL today
Build, train, and deploy models faster at scale with fully managed infrastructure, tools, and workflows.