Tutorials
09 January 2023
Hybrid Cloud for ML, Simplified
Set up a hybrid ML infrastructure with a single-line command with VESSL Clusters
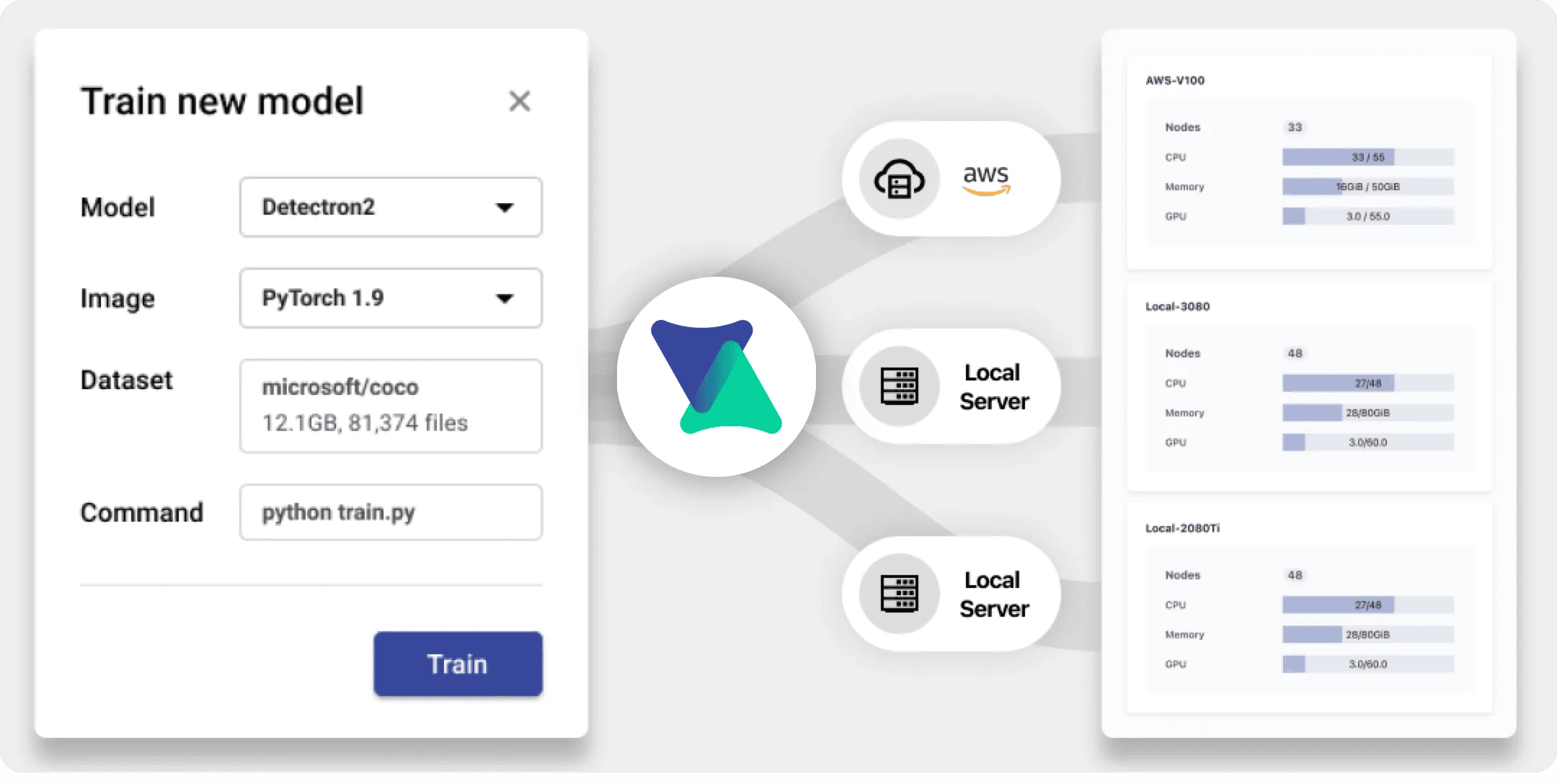
In this tutorial, we will set up a hybrid ML infrastructure using VESSL Clusters. We will also share the common challenges that ML teams face as they make the transition to hybrid cloud and the motivation behind this recent trend.
By the end of this tutorial, you will be able to use VESSL as an access point for the hybrid cloud. Scroll down to Step-by-step guide if you want to get started right away.
- 1. Set up a hybrid cloud environment for machine learning composed of a personal Linux machine and on-premise GPU servers in addition to VESSL’s managed AWS.
- 2. Dynamically allocate GPU resources to Kubernetes-backed ML workloads, specifically, notebook servers and training jobs on hybrid infrastructure.
- 3. Monitor the GPU usage and node status of on-prem clusters.

The Cost of Cloud in ML
With the rising cost of ML, companies are moving away from the cloud and taking the hybrid approach
Compute infrastructure is the key enabler for the latest developments in machine learning and yet it’s also the most complex and expensive hidden technical debt in ML systems. High-performance cloud instances such as Amazon AWS EC2 P3 and Google Cloud TPU have made HPC-grade GPUs more available, but not necessarily more accessible.
Cloud computing is here to stay but the high cost of training is one of the largest challenges that ML teams face today. Even considering the diminishing return of on-prem machines, cloud-only teams are 60% more expensive↗ than their counterparts. In extreme cases like GPT-3 which has 175 billion parameters, it and would require $4,600,000 to train↗ — even with the lowest priced GPU cloud on the market.
We’ve seen multiple customers of various sizes whose cost of cloud is putting noticeable strains on their growth and revenues:
- an early-stage vision analytics startup investing up to 30%+ of its recent Seed round in an Oracle Cloud contract
- a growth-stage ADAS company with <20 machine learning engineers spending up to $1M every month on AWS
- a 100+ people AI/ML team at Fortune 500 looking for an alternative local cloud provider to lower their dependency on Google Cloud
We’ve seen a similar trend↗ happening in the general software development — the pressure that cloud puts on margins starts to outweigh the benefits as a company scales. The emergence of cost-sensitive GPU clouds built for deep learning such as Lambda↗ and Jarvis Labs↗, and ML libraries for improving training efficiencies like MosicML↗ demonstrate that the field is maturing as well.
Cloud providers have argued that the computing requirements for ML are far too expensive and cumbersome↗ to start up on their own. However, some companies are shifting their machine learning data and models to their own machines and now investing again in their hybrid infrastructure↗ — on-prem infrastructure combined with the cloud. The result — adopters are spending less money and getting better performance.
Leveraging hybrid cloud strategy with Kubernetes
Kubernetes is helping the transition to hybrid cloud and has emerged as a key component of SW stack for ML infra
Barebone machines are only a small part of setting up modern ML infrastructures. Many of the challenges teams that face as they make transition to hybrid cloud is in fact in the software stack. The complex compute backends and system details abstracted by AWS, Google Cloud, and Azure have to be manually configured. The challenge becomes even greater if you take the ML-specific topics into account:

- Monitor cross-cluster usage and allocate temporal demand spikes to the cloud
- Mount and cache high-volume datasets across hybrid environments
- Containerize↗ current progress and move between on-prem and cloud seamlessly
Thankfully, the applications of GPU-accelerated Docker containers↗ and Kubernetes pods↗ in machine learning, along with the inflected tools from multi-cloud paradigm like MinIO↗ is enabling the transition to hybrid infrastructure. For teams looking to leverage hybrid cloud, Kubernetes has become the go-to dev tool for orchestration, deployment, scaling, and management of containerized ML workloads for reasons more than just costs:
- Ensure reproducibility — Save the build and training runtime environment as Docker images and refer them using Kubernetes to ensure consistency across on-prem and cloud.
- Optimize compute resources — Match and scale Kubernetes pods automatically based on the required hardware configurations and monitor resource consumption down to each pod.
- Improve fault-tolerance — Self-healing replaces containers that fail user-defined health checks, and taints and tolerance prevents schedulers from using physically unusable nodes.
Hybrid ML infra with VESSL Clusters
VESSL abstracts the complex compute backends of hybrid ML infra into an easy-to-use interface
Despite these benefits, Kubernetes infrastructure is hard. Everything that an application typically has to take into consideration, like security, logging, redundancy, and scaling, are all built into the Kubernetes fabric — making it heavy and inherently difficult to learn, especially for data scientists who do not have the engineering background. For organizations that have the luxury of a dedicated DevOps or MLOps team, it may still take up to 6 months to implement and distribute the tools and workflows down to every MLEs.
VESSL Clusters makes the integration, orchestration, and management of hybrid clouds simple and straightforward. It abstracts the complex compute backends and system details of Kubernetes-backed GPU infrastructure into an easy-to-use web interface and simple CLI commands

- Easy-to-use interface — Run any GPU-accelerated ML workloads with local or cloud codebase and datasets in seconds on a web interface or CLI.
- Single-command integration — Integrate on-premise servers with a single-line command and use them with multiple cloud services including VESSL’s managed cloud.
- Cluster management — Monitor real-time usage and incident status of each node on a shared dashboard and set an internal quota policy to prevent overuse.
- Job scheduling and elastic scaling — Schedule training jobs and serving workloads and scale pods for optimum performance handling.
Upon setting up a hybrid infrastructure with VESSL Clusters, you can easily provision GPU resources to launch any ML workloads including notebook workspace, job scheduler, hyperparameter optimization, and model server.

Step-by-step guide — cluster integration with VESSL
VESSL Clusters enables cluster integration in a single-line command
VESSL’s cluster integration is composed of four primitives:
- VESSL API Server enables communication between the user and the GPU clusters, through which users can launch and manage containerized ML workloads.
- VESSL Cluster Agent sends information about the clusters and workloads running on the cluster such as the node resource specifications and model metrics.
- Control plane node↗ acts as the control tower of the cluster and hosts the computation, storage, and memory resources to run all the subsidiary worker nodes.
- Worker nodes run specified ML workloads based on the runtime spec sent from the control plane node.

Try single-node cluster integration on your Mac
(1) Prerequisites
To connect your on-premise GPU clusters to VESSL, you should first have Docker and Helm↗ installed on your machine. The easiest way is to brew install. Check out the Docker↗ and Helm↗ docs for more detailed installation instructions. Keep in mind you have to sign in and keep Docker running while using VESSL clusters.
brew install dockerbrew install helm(2) Set up VESSL environment
Sign up for a free account on VESSL and pip install VESSL SDK on your Mac. Then, set up a VESSL environment on your machine using vessl configure. This will open a new browser window that asks you to grant access. Proceed by clicking grant access.
pip install vessl --upgradevessl configure
(3) Connect your machine
You are now ready to connect your Mac to VESSL. The following single-line command connects your Mac, which will appear as macbook-pro-16 on VESSL. Note the --mode single flag specifying that you will be installing a single-node cluster.
vessl cluster create --name '[CLUSTER_NAME_HERE]' --mode singleThe command will automatically check dependencies and ask you to install Kubernetes. Proceed by entering y. This process will take a few minutes.
If you have Kubernetes installed on your machine, the command will then ask you to install VESSL agent on the Kubernetes cluster. Enter y and proceed.

(4) Confirm integration
Use our CLI command to confirm your integration and try running a training job on your laptop. Your first run may take a few minutes to get the Docker images installed on your device.
vessl cluster list
Scale cluster integration on your team’s on-premise machines
Integrating more powerful, multi-node GPU clusters for your team is as easy as repeating the steps above. To make the process easier, we’ve prepared a single-line curl command that installs all the binaries and dependencies on your server. Note that Ubunto 18.04 or Centos 7.9 or higher Linux OS is installed on your server.
(1) Prerequisites
Install all the dependencies using our use our magic curl command that
- Installs Docker if it’s not already installed.
- Installs and configures NVIDIA container runtime↗.
- Installs k0s↗, a lightweight Kubernetes distribution, and designates and configures a control plane node.
- Generates a token and a command for connecting worker nodes to the control plane node configured above.
Go ahead and run the following command. Note that if you wish to use your control plane solely for control plane node — meaning not running any ML workloads on the control plane node and only using it for admin and visibility purposes — add--taint-controller flag at the end of the command.
curl -sSLf https://install.dev.vssl.ai | sudo bash -s -- --role=controllerUpon installing all the dependencies, the command returns a follow-up command with a token thatyou can use to add additional worker nodes to the control plane. Copy & paste and run the command to do so. If you don’t want to add an additional worker node, skip the step below.

curl -sSLf https://install.dev.vssl.ai | sudo bash -s -- --role worker --token '[TOKEN_HERE]'You can confirm your control plane and worker node configuration using a k0s command.
sudo k0s kubectl get nodes
(2) Integrate your machine to VESSL
Once you have completed the steps above, you can now integrate the Kubernetes cluster with VESSL. Note the --mode multi flag.
pip install vessl --upgradevessl configurevessl cluster create --name='[CLUSTER_NAME_HERE]' --mode=multi(3) Confirm integration
You can once again use our CLI command or visit Clusters page on VESSL to confirm your integration.
vessl cluster list
Wrap up
This post covers the recent trends in and motivation behind hybrid ML infrastructure while connecting your GPU clusters to VESSL using our magic, single-line command.
If you haven’t already, make sure to sign up for a free VESSL account so you can follow along. Also, check out how our education and enterprise customers like KAIST and Hyundai are scaling their on-premise severs and hybrid cloud up to 1000+ Kubernetes nodes.

If you need any support or have any additional questions while using VESSL Clusters, let us know at growth@vessl.ai or on our community Slack↗.

Yong Hee
Growth Manager
Try VESSL today
Build, train, and deploy models faster at scale with fully managed infrastructure, tools, and workflows.