Product
28 December 2023
Announcing VESSL Hub: One-click recipes for the latest open-source models
Fine-tune and deploy Llama 2, Stable Diffusion, and more with just a single click
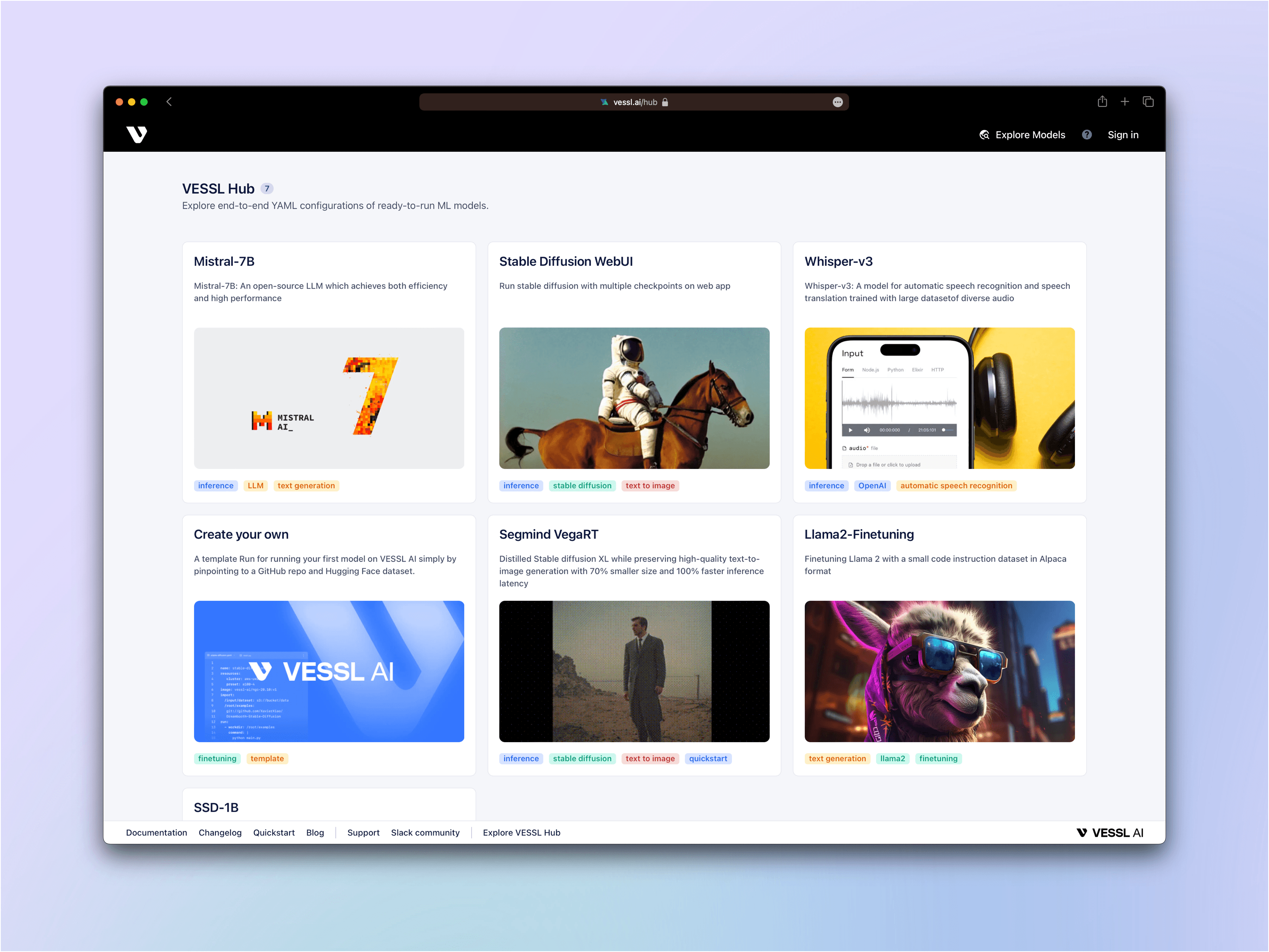
Launch the latest models at VESSL Hub
Fine-tune and deploy the latest open-source LLMs, Gen AI, and more with just a single click
- Fine-tune Llama2-7B↗ with a code instructions dataset
- Launch Interactive playground for SSD-1B↗, a lighter and faster version of Stable Diffusion XL
- Launch a text-generation Streamlit app using Mistral-7B↗
2023 in AI has been marked by open-source foundation models. Every week, we see multiple versions of models like Stable Diffusion, Llama 2, and Mistral that are better in performance, faster, and lighter — take SSD-1B↗, a 50% smaller and 60% faster version of Stable Diffusion XL. With that, companies are going beyond simply exploring these models and fine-tuning and deploying them in production. Scatter Lab, the leading Generative AI startup in Korea, for example, used VESSL AI to fine-tune an open-source large language model↗ that powers its personal AI.
Today, we are excited to extend this effort with the announcement of VESSL Hub, one-click recipes for the latest open-source models. Beginning with VESSL Run, we’ve been helping ML professionals & enthusiasts quickly put these models to work. With VESSL Run, we’ve streamlined the interface for running AI workloads on any cloud at any scale into just a simple YAML definition. VESSL Hub is a collection of these Runs, a curated list of popular models, award-winning academic papers, and GPU-accelerated AI workloads that users can instantly experiment, fine-tune, and deploy with just a click of a button.
The easiest way to explore and deploy models

Along with the latest models, VESSL Hub provides the integrated infrastructure layer to help you go seamlessly from a prototype to production. Running broken Colab notebooks and outdated GitHub repos requires hours of runtime configuration and model API services lack the cloud backends that are crucial for full-scale production use cases.
Fine-tuning and deployment, or any other GPU-accelerated AI workloads on VESSL Hub come natively with our fullstack cloud infrastructure↗. This means you will be able to scale the curated models on VESSL Hub with just a click of a button — or a single YAML file.
- Autoscaling — Dedicate more GPUs to fine-tuning and inference instances for peak usage
- Model checkpointing — Stores model checkpoints to mounted volumes or model registry and ensures seamless checkpointing of fine-tuning progress
- Model & system metrics — Keep track of model metrics and hyperparameters along with GPU usage
The models on VESSL Hub are also pre-optimized to help you get up and running faster.
- Warm pool — The pre-initialized GPU instances on our managed cloud are ready to quickly start serving and scaling workloads. Your instance will start up to 80% faster.
- Optimized Docker Images — Our custom Docker Images are now up to 80% smaller, making your instance boot-up time even faster.
- Instant volume mount — Mount cached datasets from Hugging Face or cloud storage instantly with zero setups.
The latest Gen AI & LLMs without the cost

With VESSL Hub, we are also bringing the most competitive prices for our managed GPU cloud. Considering our GPU cloud comes natively with end-to-end MLOps coverage, we are confident that we offer one of the industry’s lowest-priced cloud infrastructures for AI. In the coming months, we will be bringing pay-per-second pricing to help you save additional GPU costs.
To help you get started with the latest Gen AI & LLMs, we are also giving out $30 in GPU credits to our users. For our full compute options and prices, please refer to our documentation.
What’s next? — Bring your datasets & GPUs

We also provide the YAML files for all of our models hosted on VESSL Hub. You can tweak the key values like resources and dataset if you want to bring your own datasets and GPUs. Let’s say you are looking to build an sLLM by fine-tuning Llama2-7B. It’s a matter of simply pinpointing dataset to another Hugging Face dataset. Our vessl create cluster command on the one hand makes it easy for our enterprise customers to take full advantage of their private clouds or on-premise.
While our machine learning engineers are hard at work to bring you more models in the coming months, we will be also excited to host your models on VESSL Hub. If you are looking to contribute to our Hub by pushing your own model, get started with our YAML template↗ and reach out to us at growth@vessl.ai.

Yong Hee
Growth Manager

Kyle
Engineering Manager
Try VESSL today
Build, train, and deploy models faster at scale with fully managed infrastructure, tools, and workflows.