Tutorials
16 January 2024
Build an AI image animation app with VESSL Run and Streamlit
Learn how to quickly host Thin-Plate Spline Motion Model for Image Animation on the GPU cloud
Building a web-based AI service can be a challenge as the machine learning engineers who worked on the models are often unfamiliar with the infrastructure and interface layer of the app.
In this tutorial, we’ll explore how the combination of VESSL Run and Streamlit helps you quickly prototype and deploy AI apps on your infrastructure without spending hours on Kubernetes and JS frameworks.
You can find the final code in our GitHub repository↗.
Overview
What we’ll build
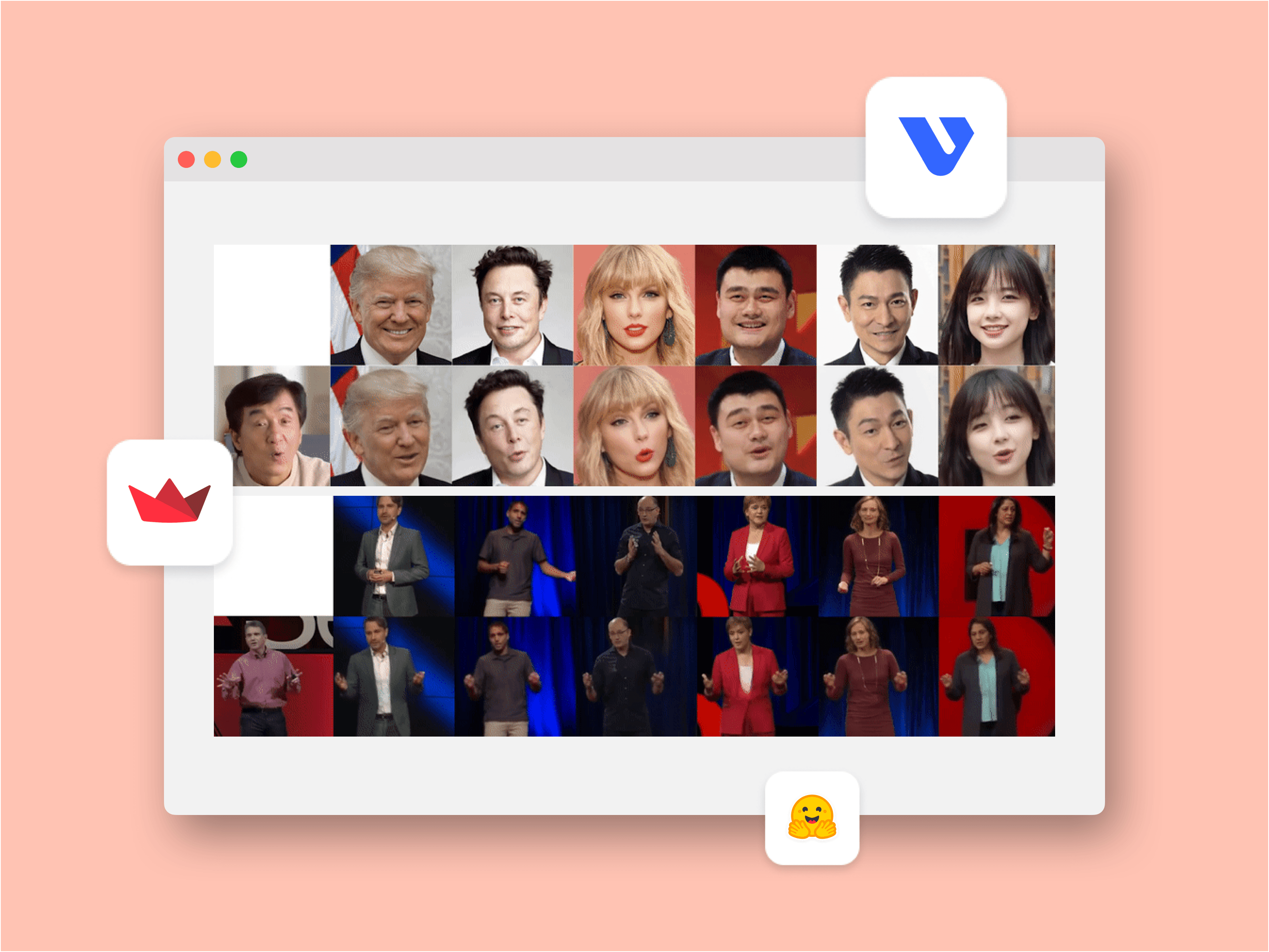
In this tutorial, we will build a simple playground for “Thin-Plate Spline Motion Model for Image Animation↗”, a motion transfer framework from CVPR 2022 on VESSL AI’s managed GPU cloud. You will also explore how you can host the app on your private infrastructure. The result looks like this.

For our model, we use the original codebase by the authors. In short, the paper introduces an image animation model that converts a static image into an animated clip following a driving video. One of the main contributions of this paper is the use of thin-plate spline motion estimation to create a more flexible optical flow. This allows for warping the feature maps of the source image to the feature domain of the driving image, which is particularly useful in scenarios where there's a large pose gap between the objects in the source and driving images.
For the infrastructure layer, we are going to use VESSL Run↗. VESSL Run abstracts the complex compute backends required to train, fine-tune, and serve containerized AI models into a unified YAML interface. With VESSL Run, you can create GPU-accelerated compute environments for inference tasks in seconds without worrying about ML-specific peripherals like cloud infrastructures, CUDA configurations, and Python dependencies.
For the interface layer, we used Streamlit↗. Streamlit is an open-source Python library that makes it easy to create and share custom web apps for machine learning. Here↗, you can see how we built our UI for the app using Python in minutes.
The combination of VESSL Run and Streamlit removes the common bottlenecks in building AI applications and in the process separates the components and the corresponding stacks for the model, infra, and interface.
What you’ll learn
- How to quickly run and deploy computationally intensive generative AI models such as LLMs as web applications.
- How to spin up a GPU-accelerated runtime environment for training, fine-tuning, and inferencing using VESSL Run.
- How to run web-based data applications using Streamlit.
Resources
Project setup
To create your runtime, first sign up for a VESSL AI account↗. You will receive $30 in free credit which is more than enough to complete and share this tutorial.
When you create your account and sign in, you will get a default Organization with our managed GPU cloud. This is where you will create a cloud runtime environment for the app. Let’s also install our Python package and set up the VESSL CLI.
pip install --upgrade vessl
vessl configureSet up a GPU-accelerated environment
With VESSL Run, setting up a runtime environment begins with defining a simple YAML definition↗. Whether you are training, fine-tuning, or serving, you start with the following skeleton and later add more key-value pairs.
name: # name of the model
resources: # resource specs
clusters:
preset:
image: # link to a Docker image
With this custom Docker image, the app is ‘run-proof’ regardless of where you run the app. Later, we will explore how you can use the same Docker image to run the app on your cloud or on-prem GPUs just by editing the value for resources, without having to spend hours PyTorch and CUDA versions. What we created is essentially a GPU-accelerated Kubernetes virtual container on the cloud.
Working with the model and codebase
You can mount codebases or volumes to the container you created above simply by referencing import. Here, we are pulling a model checkpoint from Hugging Face and the codebase from GitHub but you can bring your own cloud or local dataset↗ to build upon our app.
import:
/ckpt/: hf://huggingface.co/VESSL/thin-plate-spline-motion-model
/root/examples/:
git:
url: github.com/vessl-ai/examples.git
ref: mainWith our code mounted, we can now define our run command that will be executed as the container runs. Here we will set our default working directory, install additional libraries as defined in requirements.txt, and finally launch the Streamlit app by running run_st.py.
run:
- command: pip install -r requirements.txt && streamlit run run_st.py
workdir: /root/examples/thin-plate-spline-motion-modelOur run_st.py contains a simple web interface built with Streamlit. Here, you can see how easy it is to build an app that provides options for a driving clip, receives an image from a user, and returns an animated video — as defined in the inference function.
# ...
with _col2:
with st.form("Driving video", clear_on_submit=False):
video_path = st.file_uploader("Upload your own driving video!", type=["mp4"])
video_submit_button = st.form_submit_button(label="Submit Driving Video")
# ...with col1:
st.header("Upload image or Take your photo!")
with st.form("image", clear_on_submit=False):
image_path = st.file_uploader("Upload your image!", type=["png", "jpg", "jpeg"])
# ...def inference(vid):
os.system(
f"python demo.py --config config/vox-256.yaml --checkpoint /ckpt/vox.pth.tar --source_image 'temp/image.jpg' --driving_video {vid} --result_video './temp/result.mp4'"
)
return "./temp/result.mp4"Deploying the app
The last step in our YAML is to set up deployment options for our app. We’ll set the runtime hours and open up a port for the container. The interactive field provides multiple ways to interact with the container such as through JupyterLab, SSH, or custom services via specified ports.
interactive:
max_runtime: 24h
jupyter:
idle_timeout: 120m
ports:
- name: streamlit
type: http
port: 8501We can now run the completed YAML file using the vessl run command. It may take a few minutes to get the instance started.
vessl run create -f thin-plate-spline-motion-model.ymlThe command reads the YAML file and
Spins up a GPU-accelerated Kubernetes on VESSL AI GPU cloud.
Sets the runtime environment for the model using the Docker Image.
Mounts the model checkpoint from Hugging Face and codebase from GitHub.
Executes run commands and launch the Streamlit app.
Enables a port for the app.
You can see the app in action by following the URL and entering a prompt.
What’s next
In this tutorial, we explored how you can use VESSL Run along with Streamlit to quickly spin up a GPU-backed AI application. We prepared additional models and resources at VESSL Hub a curated list of one-click recipes for hosting, training, fine-tuning, and deploying the latest models.

- Fine-tune Llama2-7B↗ with a code instructions dataset
- Launch a text-generation Streamlit app using Mistral-7B↗
- Interactive playground of SSD-1B↗ a lighter and faster version of Stable Diffusion XL
If you haven’t already, make sure to sign up for a free VESSL account↗ so you can follow along. If you have any additional questions or requests for future tutorials, let us know by contacting us at support@vessl.ai.

Yong Hee
Growth Manager
David Oh
ML Engineer Intern
Try VESSL today
Build, train, and deploy models faster at scale with fully managed infrastructure, tools, and workflows.