Machine Learning
17 November 2023
3 YAMLs we shared at MLOps World — Llama2c playground to production
LLMOps infrastructure for prototyping, fine-tuning, and deploying LLM, simplified into 3 YAMLs
Last week, we were at MLOps World 2023 where we shared three YAML files that abstract the complex AI & LLMOps infrastructure for (1) creating a simple demo space for LLMs, (2) fine-tuning LLMs with proprietary datasets, and (3) deploying them into production on a robust AI infrastructure.
These YAML files work together with our vessl run commands to help AI teams quickly explore different LLMs and accelerate time-to-production by handling complex backends ranging from allocating the right GPU resource to creating inference endpoints. Follow along with our three YAML files on Llama2.c below to learn how you can go from an LLM prototype to deploying fine-tuned LLMs on the cloud.
Playground

As companies explore different open-source LLMs, they often want to get started by setting up a simple demo space similar to Hugging Face Spaces. Milestone models like Llama 2 and Stable Diffusion have multiple versions and iterations. With tools like Streamlit↗, VESSL AI helps data teams test these variations on their own GPU infrastructure whether that’s on cloud or on-prem.
vessl run create llama2c_playground.yamlname: llama2c_playground
description: Batch inference with llama2.c on a persistent runtime.
resources:
cluster: aws-apne2
preset: v1.cpu-2.mem-6
image: quay.io/vessl-ai/ngc-pytorch-kernel:23.07-py3-202308010607
import:
/root/examples/: git://github.com/vessl-ai/examples.git
run:
- command: pip install streamlit
workdir: /root/examples
- command: wget https://huggingface.co/karpathy/tinyllamas/resolve/main/stories42M.bin
workdir: /root/examples/llama2_c
- command: streamlit run llama2_c/streamlit/llama2_c_inference.py --server.port=80
workdir: /root/examples
interactive:
max_runtime: 24h
jupyter:
idle_timeout: 120m
ports:
- name: streamlit
type: http
port: 80- Launch GPU accelerated runtime instantly without the CUDA and pip headaches by running the
vessl runcommand. The command runs a persistence runtime on the cloud for hosting data apps, including Jupyter notebooks. Here we are launching a Llama2.c inference demo app built with Streamlit which you can access through the dedicated port. - Launch similar data apps on different clouds or spec'ed out on-prems by simply tweaking values under
resources.
resources:
cluster: DGX-A100
preset: gpu-1.cpu-12.mem-40- Plug and play different models by referencing their GitHub repositories directly under
importor simplygit cloneorwgetunder theruncommand.
imports:
/root/examples: git://github.com/deep-diver/LLM-As-Chatbot.git
# /root/examples: git://github.com/vessl-ai/examples.gitFine-tuning
As teams progress beyond a simple playground, they want to use their proprietary datasets to fine-tune models. VESSL AI provides the simplest interface for (1) loading pre-trained models, (2) plugging in multiple data sources, and (3) tweaking LLM-specific parameters like temperature and context window in addition to traditional hyperparameters like batch size and learning rate. Behind the scenes, VESSL AI also serves as a scalable and reliable infrastructure for LLM-scale models.
name: llama2_c_training
description: Fine-tuning llama2_c with VESSL Run.
resources:
cluster: aws-apne2
preset: v1.v100-1.mem-52
image: quay.io/vessl-ai/ngc-pytorch-kernel:23.07-py3-202308010607
import:
/my-dataset: vessl-dataset://myOrg/myDataset # Import the dataset from VESSL Dataset
/pretrained-model: vessl-model://myOrg/llama2/1 # Import the pretrained model from VESSL Model Registry
/root/examples/: git://github.com/vessl-ai/examples.git # Import the code from GitHub Repository
export: # Export "/output" directory to VESSL Model Registry
/output: vessl-model://myOrg/llama2
run:
- workdir: /root # Install python requirements
command: |
pip install -r requirements.txt
- workdir: /root/examples/llama2_c # Tokenize the input dataset
command: |-
python tinystories.py pretokenize --dataset_dir=$dataset_dir
- workdir: /root/examples/llama2_c # Train with the toknized dataset
command: |
python -m train --model_dir=$model_dir --dataset_dir=$dataset_dir --compile=False --eval_iters=$eval_iters --batch_size=$batch_size --max_iters=$max_iters
- workdir: /root/examples/llama2_c # Inference once for validation
command: |-
gcc -O3 -o run run.c -lm
./run out/model.bin
- workdir: /root/examples/llama2_c # Copy the trained model to /ouput directory
command: cp out/model.bin /output
env: # Set arguments and hyperparameters as environment variables
dataset_dir: "/my-dataset"
model_dir: "/pretrained-model"
batch_size: "8"
eval_iters: "10"
max_iters: "10000"- Quickly import pre-trained data from Hugging Face Models or VESSL AI’s managed model registry simply by referencing the model under
/pretrained-model. - Mount datasets from AWS S3, VESSL AI managed storage, local storage, and more directly to the fine-tuning runtime by referencing multiple volumes under
/my-dataset.
imports:
/my-dataset1: vessl-dataset://myOrg/myDataset
# /my-dataset2: s3://myOrg/myDataset
# /my-dataset3: nfs://local/myDataset
# /my-dataset4:/datasets/sharegpt.json: https://huggingface.co/datasets/anon8231489123/ShareGPT_Vicuna_unfiltered/resolve/main/ShareGPT_V3_unfiltered_cleaned_split.json
- Use our Python SDK
vessl.log()to reference and tweak variables underenv. As teams experiment, VESSL AI’s experiment artifacts and model registry keep all records of these values. - Behind the scenes, VESSL AI abstracted features like automatic failover, autoscaling, and model checkpointing which work in coordination to ensure that your fine-tuning jobs that take days and $10Ks to complete are run-proof.
Deployment
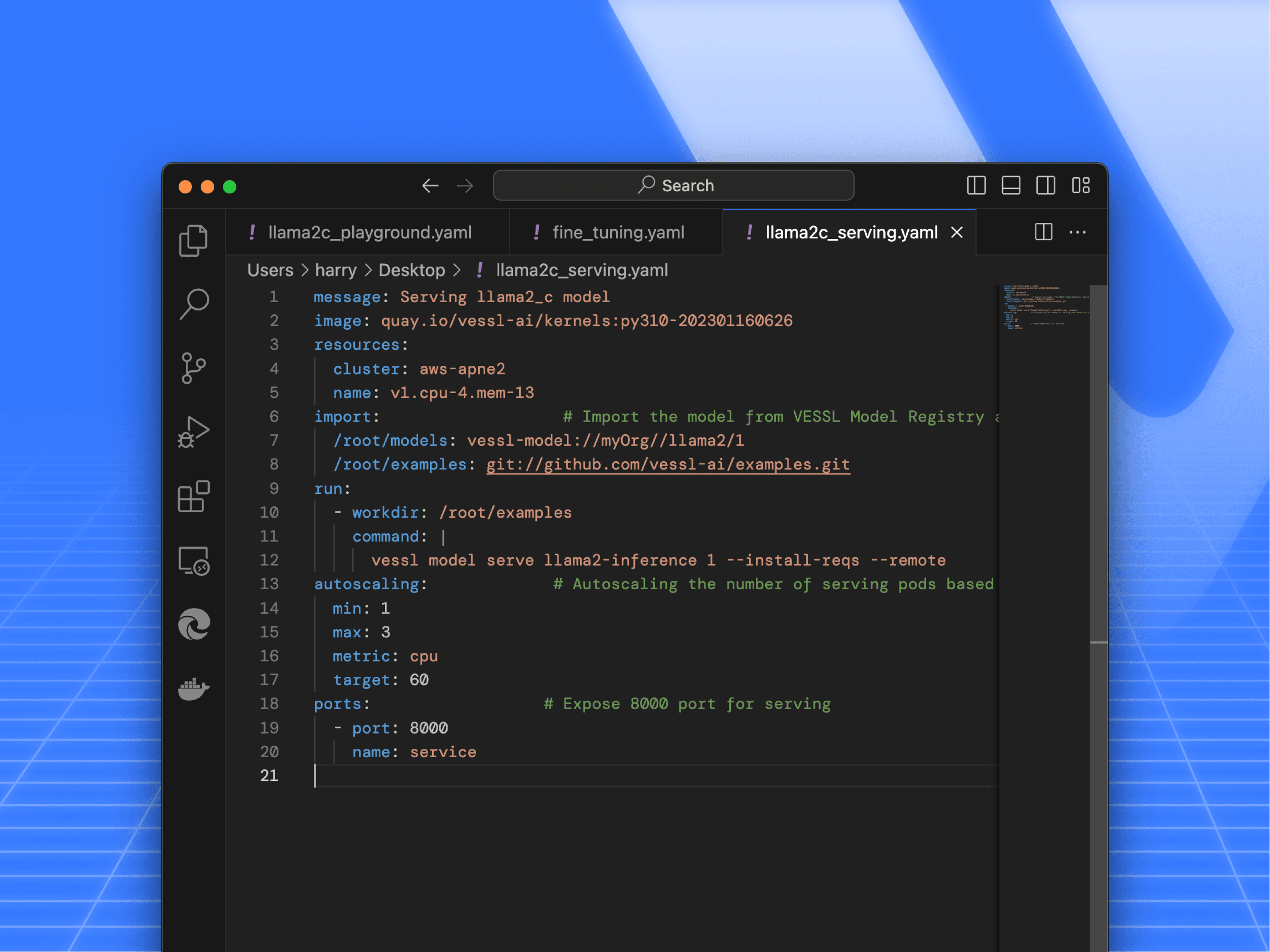
Deploying models into production requires (1) setting up a highly scalable GPU workload for peak uses, (2) accepting user inputs through designated ports and endpoints, (3) and processing inference in a few milliseconds. These are often SW engineering challenges that typical data scientists and ML practitioners may not be familiar with. With the same YAML definition and native support for open-source tools like vLLM↗, VESSL AI offloads these overheads and helps LLM serving accessible and affordable even for small teams.
message: Serving llama2_c model
image: quay.io/vessl-ai/kernels:py310-202301160626
resources:
cluster: aws-apne2
name: v1.cpu-4.mem-13
import: # Import the model from VESSL Model Registry and the inference code from GitHub Repository
/root/models: vessl-model://myOrg//llama2/1
/root/examples: git://github.com/vessl-ai/examples.git
run:
- workdir: /root/examples
command: |
vessl model serve llama2-inference 1 --install-reqs --remote
autoscaling: # Autoscaling the number of serving pods based on the CPU utilization
min: 1
max: 3
metric: cpu
target: 60
ports: # Expose 8000 port for serving
- port: 8000
name: service
type: http
- Expose a port for serving by simply designating a port number. You can also set up multiple ports and allocate traffic to each port, which allows you to A/B test your models. VESSL AI routes incoming traffic to service workloads using Kubernetes Ingress and TrafficSplit.

- Once you set up an endpoint, you will be ablee to use a
curlcommand to see the model in action. The command below will send the input prompt through the port exposed above.
curl -X 'POST' \
'https://model-service-gateway-uiitfdji1wx7.managed-cluster-apne2.vessl.ai/generate/' \
-H 'accept: application/json' \
-H 'Content-Type: application/json' \
-d '{"prompts": "Once upon a time, Floyd"}'
- Make sure your LLM service is ready for peak usage by setting up autoscaling. Here, VESSL AI automatically increases CPU cores whenever the usage threshold goes beyond 60%. For relatively low usage or idle time, it will automatically decrease the usage down to a single CPU core. Of course, you can set the same specifications for your GPUs.
autoscaling:
min: 1
max: 3
metric: cpu
target: 60At MLOps World 2023, we’ve seen a broad pattern that Enterprises building generative AI first select the LLM, fine-tune it with new data, and provide context by attaching relevant reference data within the LLM prompts. This process of adapting a pre-trained generative LLM often requires orders of magnitude more computing than ML models, incurring significant infrastructural challenges that often take weeks just to map out.
VESSL AI solves this problem starting as a runtime infrastructure, bringing a more streamlined and cost-effective workflow that optimizes how the compute scales across prototyping-to-production. We’ve simplified the complex LLMOps tech stack into a few YAMLs teams like Scatter Lab are already using them to fine-tune and deploy service-grade LLMs.
You can try these YAMLs with just a single click by heading over to VESSL Hub↗, where we prepared pre-defined YAMLs for the latest LLMs like Llama2.c, Mistral 7B, and SSD-1B.
Try VESSL today
Build, train, and deploy models faster at scale with fully managed infrastructure, tools, and workflows.