Tutorials
12 March 2024
Build an interactive chatbot application with Gemma 2b-IT using Streamlit and VESSL Run
Learn to host Gemma 2b-IT for interactive conversations on the GPU cloud using Streamlit and VESSL Run.
Developing a web-based AI service can be daunting, especially for machine learning engineers who are experts in model training but not in web infrastructure or frontend design.
In this tutorial, we will demonstrate how the synergy of VESSL Run and Streamlit simplifies the task, enabling you to swiftly launch AI-driven applications like the Gemma 2b-IT chatbot. This method eliminates the complexities associated with direct infrastructure management, such as Kubernetes or frontend coding. You can find the final code in our GitHub repository↗.
Overview
What we'll build
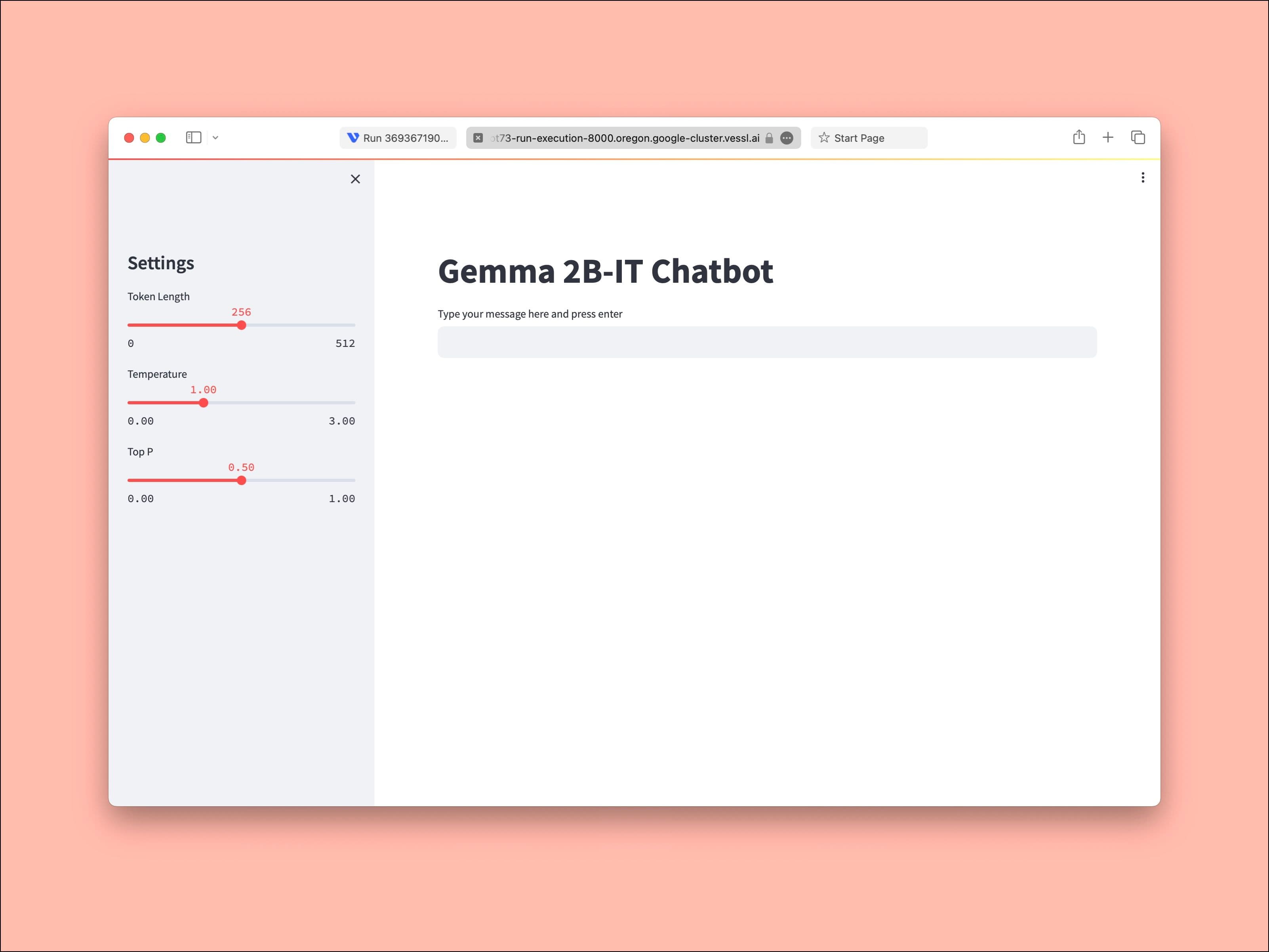
In this tutorial, we will create a simple playground for the "Gemma 2b-IT" model, a cutting-edge language processing tool developed by Google. Hosted on VESSL AI’s advanced GPU cloud, this application allows users to experience real-time, interactive dialogues with an AI entity. Additionally, we will cover how to deploy this AI chatbot on your own infrastructure. The result looks like this.

For our implementation, we harness the original Gemma 2b-IT codebase. Essentially, this model exemplifies the forefront of natural language processing, enabling users to engage in detailed, context-aware dialogues. One of the notable features of Gemma 2b-IT is its adeptness at maintaining the flow and relevance of conversations, mimicking a natural, human-like exchange. This becomes particularly advantageous in more complex dialogue scenarios where maintaining context is crucial.
For the infrastructure layer, we are going to use VESSL Run↗. VESSL Run abstracts the complex compute backends required to train, fine-tune, and serve containerized AI models into a unified YAML interface. With VESSL Run, you can create GPU-accelerated compute environments for inference tasks in seconds without worrying about ML-specific peripherals like cloud infrastructures, CUDA configurations, and Python dependencies.
For the interface layer, we used Streamlit↗. Streamlit is an open-source Python library that makes it easy to create and share custom web apps for machine learning. Here↗, you can see how we built our UI for the app using Python in minutes.
The combination of VESSL Run and Streamlit removes the common bottlenecks in building AI applications and in the process separates the components and the corresponding stacks for the model, infra, and interface.
What you’ll learn
- How to quickly run and deploy computationally intensive generative AI models such as LLMs as web applications.
- How to spin up a GPU-accelerated runtime environment for training, fine-tuning, and inferencing using VESSL Run.
- How to run web-based data applications using Streamlit.
- How to integrate Hugging Face authentication tokens into your application's YAML configuration for secure model access and deployment.
Resources
Project Setup
To create your runtime, first sign up for a VESSL AI account↗. You will receive $30 in free credit which is more than enough to complete and share this tutorial.
When you create your account and sign in, you will get a default Organization with our managed GPU cloud. This is where you will create a cloud runtime environment for the app. Let’s also install our Python package and set up the VESSL CLI.
pip install --upgrade vessl
vessl configureSet up a GPU-accelerated environment
With VESSL Run, setting up a runtime environment begins with defining a simple YAML definition↗. Whether you are training, fine-tuning, or serving, you start with the following skeleton and later add more key-value pairs.
name: # name of the model
resources: # resource specs
clusters:
preset:
image: # link to a Docker imageFor our image animation app, we will utilize an L4↗ small instance on our managed GCP. NVIDIA L4 Tensor Core GPUs are tailored for tasks like image generation and animation. Opting for the more precise L4 small variant over the commonly used NVIDIA A10G allows teams to maintain significant savings in infrastructure costs — up to 40% — while still achieving improved performance, typically 2-4x compared to NVIDIA T4 GPUs. This makes L4 small an ideal choice for efficiently managing resource-intensive tasks without compromising on output quality.
# interacactive-gemma.yaml
name: interacactive-gemma
description: # resource specs
resources:
cluster: vessl-gcp-oregon
preset: gpu-l4-small-spot
image: quay.io/vessl-ai/torch:2.2.0-cuda12.3-r4With this custom Docker image, the app is ‘run-proof’ regardless of where you run the app. Later, we will explore how you can use the same Docker image to run the app on your cloud or on-prem GPUs just by editing the value for resources, without having to spend hours PyTorch and CUDA versions. What we created is essentially a GPU-accelerated Kubernetes virtual container on the cloud.
Working with the model and codebase
You can mount codebases or volumes to the container you created above simply by referencing import. Here, we are pulling a model checkpoint from Hugging Face and the codebase from GitHub but you can bring your own cloud or local dataset↗ to build upon our app.
import:
/root/:
git:
url: github.com/vessl-ai/examples.git
ref: mainWith our code mounted, we can now define our run command that will be executed as the container runs. Here we will set our default working directory, install additional libraries as defined in requirements.txt, and finally launch the Streamlit app by running app.py.
transformers
accelerate
streamlit
torch
streamlit-chatthe next step involves installing the required Python packages to ensure our application functions smoothly. Included in our requirements.txt file↗ are essential libraries such as transformers, accelerate, streamlit, torch, and streamlit-chat, tailored specifically to support the functionalities of our AI model and web application.
In the run command section of our container setup, we will execute pip install -r requirements.txt. This command efficiently handles the installation of all listed dependencies, setting the stage for our Streamlit application to run effectively without additional manual setup.
run:
- command: |-
pip install -r requirements.txt
streamlit run app.py --server.port 8000
workdir: /root/gemmaTo ensure secure access to Hugging Face models and resources within your application, it's crucial to incorporate your Hugging Face authentication token into the YAML configuration file. This token facilitates authorized API calls and model downloads directly from Hugging Face, enhancing the security and efficiency of your deployment process.
env:
HF_TOKEN: (Add your own Hugging Face Token)Add the following lines to the end of your YAML file above and replace (Add your own Hugging Face Token) with your actual Hugging Face token. By doing this, you grant your application secure access to necessary models and libraries, enabling seamless integration and utilization of Hugging Face's extensive resources.
# Chat window setup
st.title("Gemma 2B-IT Chatbot")
user_input = st.text_input("Type your message here and press enter", key="input")
if user_input:
# Convert input text to tokens
input_ids = tokenizer.encode(user_input, return_tensors="pt")
input_ids = input_ids.to(model.device)
# Convert generated tokens to string
response = tokenizer.decode(output_ids[0], skip_special_tokens=True)
# Display response in a nicer format
col1, col2 = st.columns([1, 4]) # Adjust the ratio as needed
with col1:
st.write("You:")
with col2:
st.write(user_input)
col1, col2 = st.columns([1, 4]) # Repeat the column layout for the response
with col1:
st.write("Gemma:")
with col2:
st.write(response, unsafe_allow_html=True) # Use unsafe_allow_html if needed for formattingOur app.py contains a simple web interface built with Streamlit like above.
Deploying the app
The last step in our YAML is to set up deployment options for our app. We’ll set the runtime hours and open up a port for the container. The interactive field provides multiple ways to interact with the container such as through JupyterLab, SSH, or custom services via specified ports.
interactive:
max_runtime: 24h
jupyter:
idle_timeout: 120m
ports:
- name: streamlit
type: http
port: 8000We can now run the completed YAML file using the vessl run command. It may take a few minutes to get the instance started.
vessl run create -f interacactive-gemma.ymlThe command reads the YAML file and
Spins up a GPU-accelerated Kubernetes on VESSL AI GPU cloud.
Sets the runtime environment for the model using the Docker Image.
Mounts the model checkpoint from Hugging Face and codebase from GitHub.
Executes run commands and launch the Streamlit app.
Enables a port for the app.
can see the app in action by following the URL and entering a prompt.
What's next

In this tutorial, we explored how you can use VESSL Run along with Streamlit to quickly spin up a GPU-backed AI application. We prepared additional models and resources at VESSL Hub a curated list of one-click recipes for hosting, training, fine-tuning, and deploying the latest models.
- Fine-tune Llama2-7B↗ with a code instructions dataset
- Launch a text-generation Streamlit app using Mistral-7B↗
- Interactive playground of SSD-1B↗ a lighter and faster version of Stable Diffusion XL
If you haven’t already, make sure to sign up for a free VESSL account↗ so you can follow along. If you have any additional questions or requests for future tutorials, let us know by contacting us at support@vessl.ai.

Kelly
Head of Global Operations
Try VESSL today
Build, train, and deploy models faster at scale with fully managed infrastructure, tools, and workflows.